























































































Introduction
Web scraping is now considered an essential skill for data analysis and development. It helps one obtain structured information from the Internet. Starbucks Menu Data Scraping with Python is a great practice when dealing with HTML structures and obtaining dynamic data. This article explains how to Extract Starbucks Coffee Menu Details Using LXML, a robust and efficient Python library for parsing HTML and XML documents.
The Starbucks menu is an interesting challenge, with diverse data in the form of drink names, categories, prices, and descriptions primarily structured in nested HTML. You can scrape this for analysis or educational purposes using Python and the LXML library. This solution requires you to inspect the website's HTML structure to identify relevant elements and then parse and extract the information using Python.
The process also demonstrates how to work with other tools like the requests library for HTTP requests and BeautifulSoup for initial exploration. By following the steps in this tutorial on Starbucks Menu Data Scraping Using Python and LXML, you'll learn how to build an automated scraper while maintaining ethical and legal boundaries and ensuring compliance with the website's terms of service.
Understanding the Goal and Tools Needed
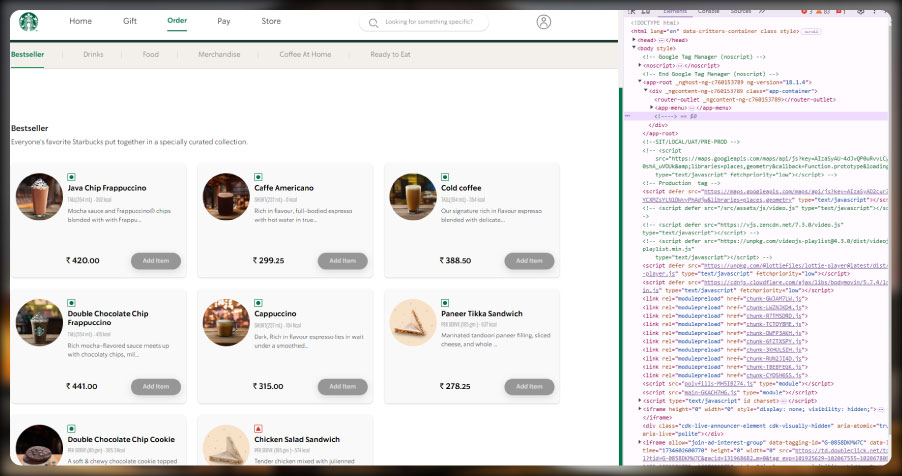
This tutorial aims to Scrape Starbucks Menu Prices using LXML and Python. It directly extracts essential menu details such as drink names, categories, prices, and descriptions from Starbucks' website or app. The LXML library in Python allows you to parse and analyze the HTML and XML documents that hold the menu data. This tutorial is best for learning Starbucks Menu Data Extraction with LXML in Python, providing a hands-on approach to web scraping.
You must install Python on your system and the LXML library to parse HTML. The requests library is handy for sending HTTP requests, while BeautifulSoup can be helpful when checking out the web page's structure during the initial setup. By checking out the HTML layout of the Starbucks menu page, you should be able to find relevant tags and attributes, such as div or span, that contain the information you want.
This step-by-step guide shows how to Scrape Starbucks Store Menu Details with LXML efficiently and accurately. It could be used to extract data for analysis, education, or other non-commercial purposes while following the best practices of compliance with ethics and the accuracy of results.
Significance of Scraping Starbucks Menu Data Using Python and LXML
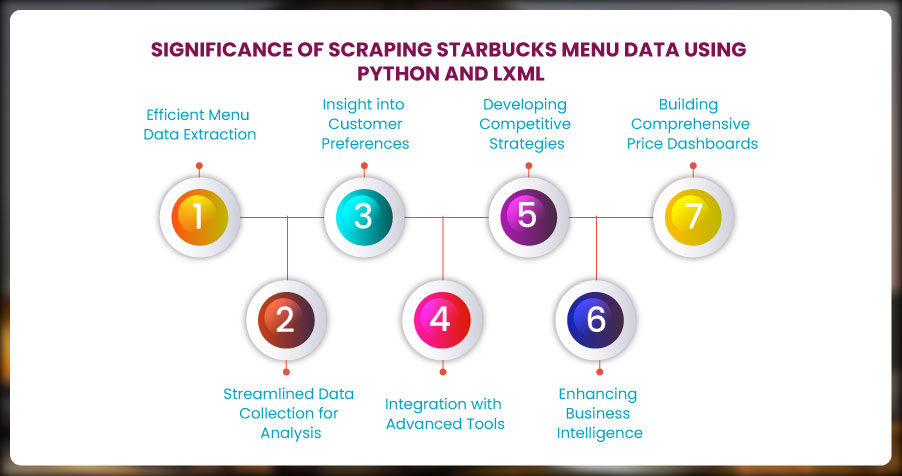
Scraping Starbucks menu data using Python and LXML offers significant benefits, from efficient data collection to actionable business insights. It supports advanced analysis, competitive strategies, and price monitoring, empowering businesses with vital information for food delivery and restaurant intelligence services.
- Efficient Menu Data Extraction: Scraping Starbucks menu data using Python and LXML enables the efficient extraction of structured information like drink names, categories, descriptions, and prices. This capability is invaluable for businesses offering Food Delivery Data Scraping Services , as it provides up-to-date menu information critical for competitive analysis and better customer experience.
- Streamlined Data Collection for Analysis: Using web scraping techniques, you can automate the gathering of menu details, saving time and resources. This automation is a cornerstone of Web Scraping Food Delivery Data, providing scalable solutions for analyzing changing menu trends and seasonal offerings.
- Insight into Customer Preferences: Scraped data can reveal customer preferences by categorizing popular menu items, seasonal trends, and price variations. Such insights are crucial for businesses focusing on Restaurant Menu Data Scraping , empowering them to effectively tailor offerings to market demands.
- Integration with Advanced Tools: Leveraging Food Delivery Scraping API Services allows businesses to seamlessly integrate scraped data into dashboards, analytics platforms, or marketing tools, creating actionable insights and streamlining operational strategies.
- Developing Competitive Strategies: Businesses can craft strategies to enhance their offerings by analyzing competitors' menu data. With Food Delivery Intelligence Services , organizations can identify pricing gaps, explore new trends, and better position themselves in the food delivery market.
- Enhancing Business Intelligence: Scraped Starbucks menu data can be utilized as part of Restaurant Data Intelligence Services , aiding in market research, menu optimization, and demand forecasting. This structured data supports decisions that align with current customer demands and future opportunities.
- Building Comprehensive Price Dashboards: Compiling scraped menu data into a Food Price Dashboard allows businesses to monitor pricing changes across various locations, helping them ensure consistency, identify trends, and make pricing adjustments to remain competitive.
Legal and Ethical Considerations
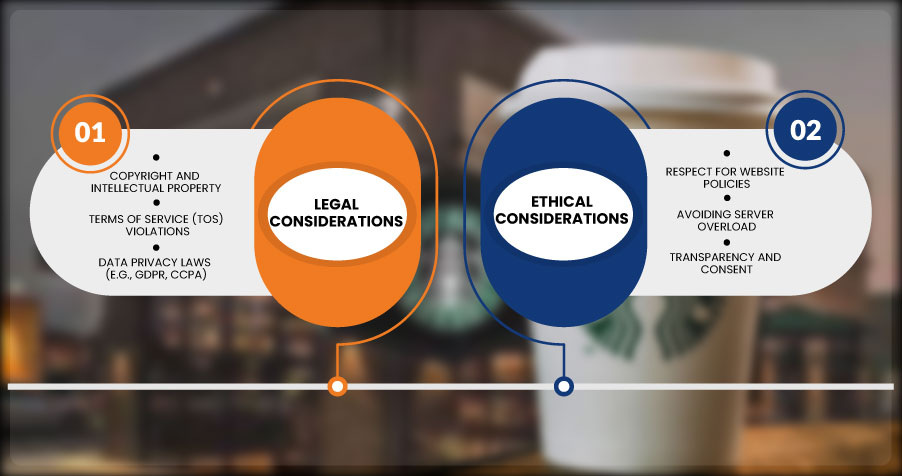
The main objective of this tutorial is to Scrape Starbucks Menu Prices effectively Using LXML and Python. This involves extracting essential menu details such as drink names, categories, prices, and descriptions directly from Starbucks' website or app. Using the LXML library in Python, you can parse and analyze the HTML and XML documents that contain the menu data. This tutorial is ideal for learning Starbucks Menu Data Extraction with LXML in Python, providing a hands-on approach to web scraping.
To begin, you'll need Python installed on your system and the LXML library for HTML parsing. The requests library helps send HTTP requests, while BeautifulSoup can aid in exploring the web page's structure during the initial setup. By examining the HTML layout of the Starbucks menu page, you can identify the relevant tags and attributes, such as div or span, that store the desired information.
This step-by-step guide will demonstrate how to Scrape Starbucks Store Menu Details with LXML, making the process efficient and accurate. Whether you're extracting data for analysis, education, or other non-commercial purposes, this method ensures ethical compliance and reliable results.
Inspecting the Website's Structure
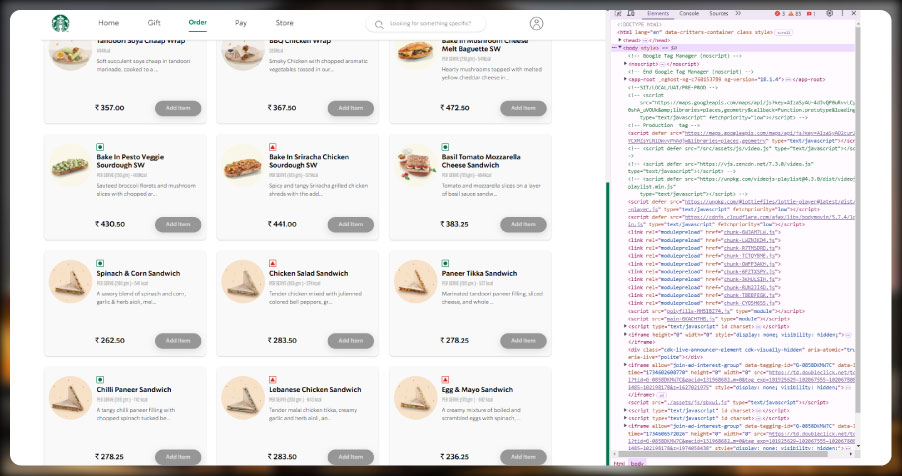
To start with Starbucks Restaurant Menu Data Collection, identify the URL of the Starbucks menu page you want to scrape. Open the webpage in a browser, right-click, and select Inspect or press Ctrl + Shift + I to access the developer tools. Carefully examine the page's HTML structure to locate the tags and attributes containing menu data. Look for elements such as div, span, or ul that include product categories, item names, and prices. This step is critical for successful Starbucks Restaurant Data Scraping , ensuring you extract accurate and well-structured information for your project.
Setting Up Your Environment
Ensure your Python environment is set up correctly. Install the required libraries by running the following commands in your terminal or command prompt:
pip install lxml requests beautifulsoup4Create a new Python file, and import the necessary modules:
import requests
from lxml import html
These libraries will allow you to fetch the webpage's content and parse it effectively using XPath selectors.
Sending a Request to the Website
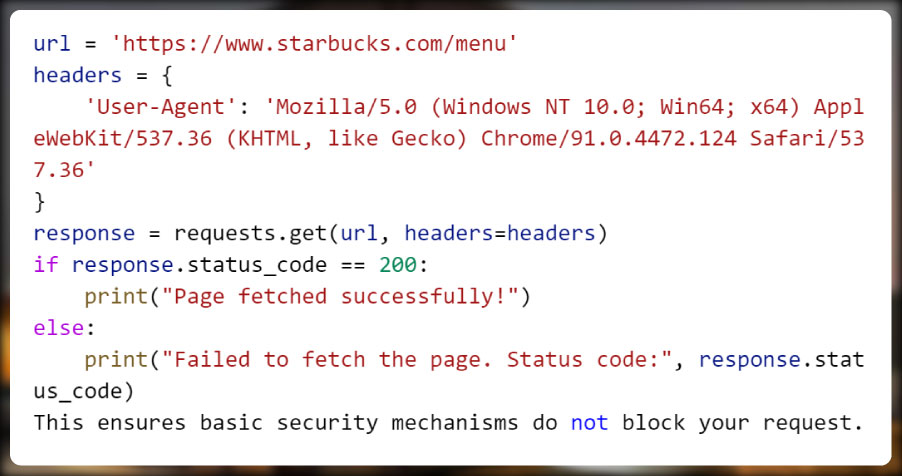
The first step in scraping is to fetch the webpage's HTML. Use the requests library to send an HTTP GET request to the Starbucks menu URL. Pass appropriate headers to mimic a legitimate browser request:
This ensures basic security mechanisms do not block your request.
Parsing HTML with LXML
Once the webpage is fetched, you can parse the HTML content using LXML. The html.fromstring method converts the raw HTML into a tree structure, allowing you to use XPath to locate specific elements:
tree = html.fromstring(response.content)The tree structure makes navigating the HTML easy and extracting the required data efficiently.
Writing XPath Expressions to Extract Data
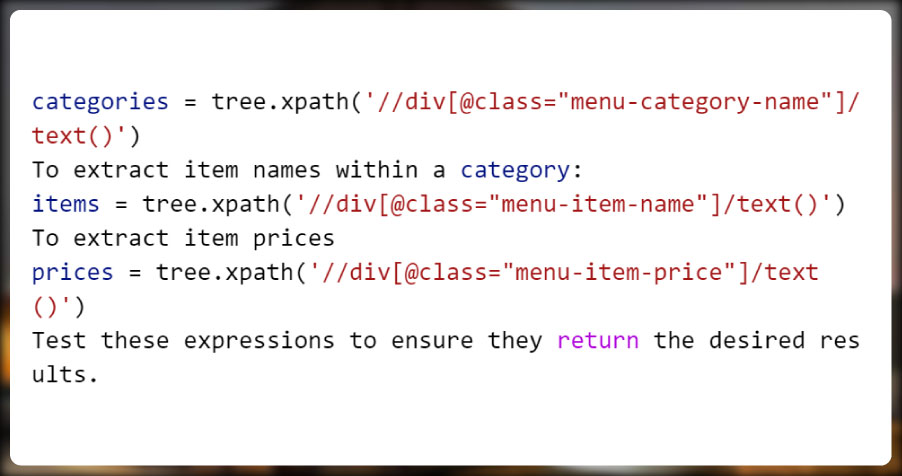
Handling Dynamic Data with JavaScript
Starbucks' website might load some menu details dynamically using JavaScript. In such cases, the raw HTML fetched via requests may not contain the required data. Tools like Selenium can render JavaScript content, but for LXML-based solutions, check if the data is available in API responses or as embedded JSON within the HTML.
Search for script tags containing data structures during inspection to locate embedded JSON.
Organizing Extracted Data
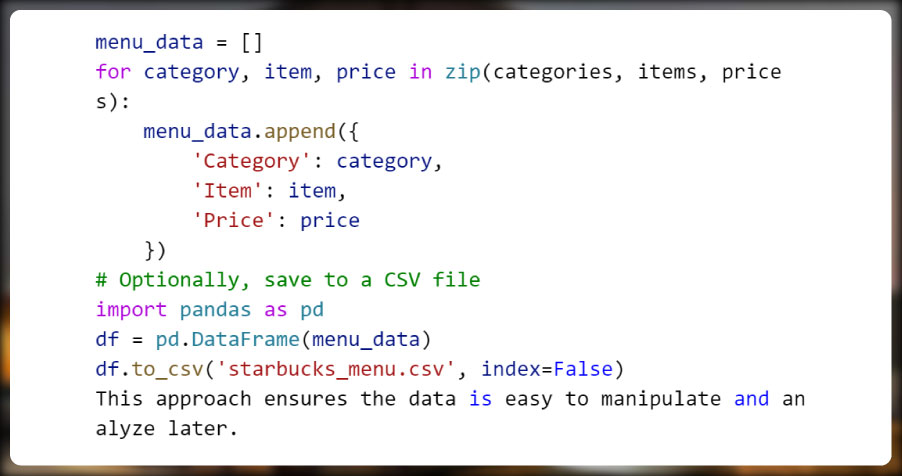
Store the extracted data in a structured format such as a dictionary or a Pandas DataFrame. For example:
This approach ensures the data is easy to manipulate and analyze later.
Handling Pagination or Infinite Scroll
Identify the mechanism to load additional data if the menu spans multiple pages or employs infinite scrolling. Often, this involves capturing API endpoints or simulating user interactions. If an API is involved, inspect the network traffic in the browser's developer tools to find the API URL and parameters.
For infinite scroll, you may need to dynamically load more content using Selenium or fetch additional data with requests.
Dealing with Errors and Edge Cases

Errors can occur during scraping due to changes in website structure, network issues, or missing elements. Implement error handling to ensure the script runs smoothly:
Additionally, validate the extracted data to avoid processing incomplete or incorrect information.
Optimizing Performance
Web scraping performance can degrade if the page is heavy or contains numerous elements. To improve efficiency, limit the scope of your XPath queries and use caching mechanisms where possible. For large-scale scraping, consider multithreading or asynchronous requests.
Respecting Website Etiquette
Always scrape responsibly by respecting robots.txt files and rate-limiting your requests. Use tools like time.sleep() to introduce delays between requests, minimizing the risk of getting blocked.
import time
time.sleep(2) # Delay for 2 seconds
This ensures you do not overwhelm the website's server.
Testing and Debugging
Before running the script on the entire website, test it on a small subset of pages or items to ensure accuracy. Debug any issues by printing intermediate outputs and refining your XPath expressions.
print(tree.xpath('//div[@class="menu-category-name"]/text()'))
This step-by-step testing helps pinpoint errors quickly.
Future-Proofing Your Script
Websites frequently update their structures, potentially breaking scraping scripts. To future-proof your code, document the XPath expressions and periodically review the website for changes. Keeping your script modular also makes it easier to update specific components.
Conclusion
Learning to Scrape Starbucks Food Delivery Data using Python and LXML is a valuable web scraping exercise. By setting up your environment, inspecting the webpage structure, utilizing XPath for data extraction, and managing dynamic content, you can efficiently gather a Starbucks Coffee Dataset with structured menu details like drink names, prices, and categories. Always adhere to ethical guidelines and handle data responsibly to ensure compliance. For more efficient solutions, consider leveraging Starbucks Food Delivery Scraping API Services to automate the process and collect data seamlessly for analysis or other non-commercial purposes.
If you are seeking for a reliable data scraping services, Food Data Scrape is at your service. We hold prominence in Food Data Aggregator and Mobile Restaurant App Scraping with impeccable data analysis for strategic decision-making.





