






















































































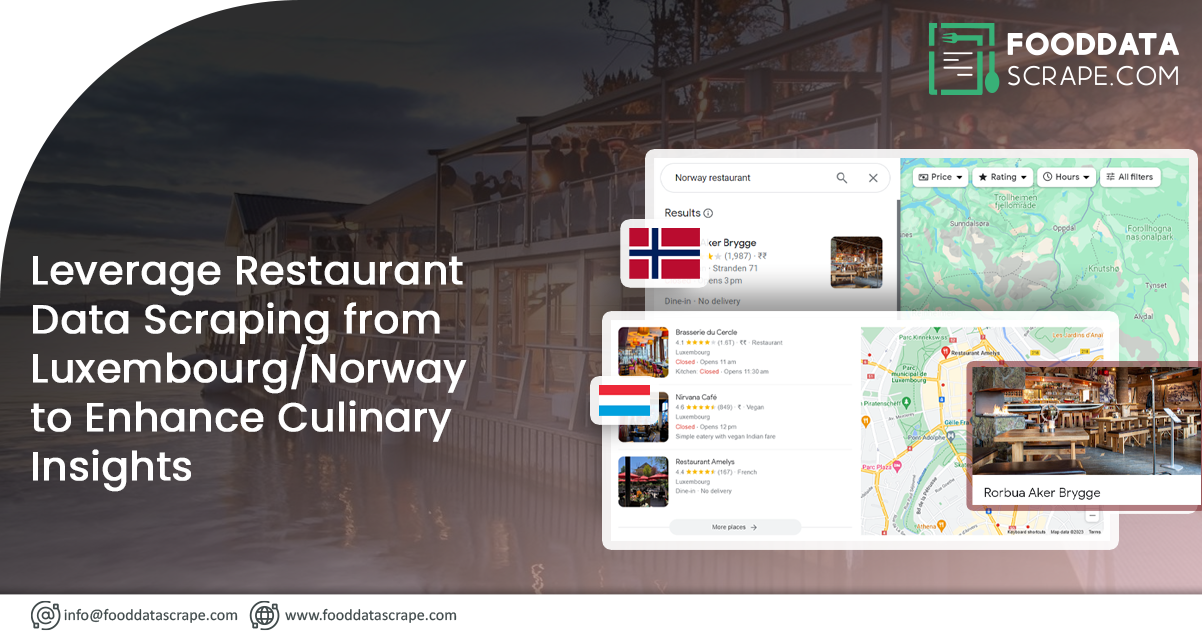
Introduction: Embarking on a culinary exploration of Luxembourg and Norway involves tapping into the rich tapestry of online restaurant data. In the digital age, web scraping restaurant data serves as a powerful tool for enthusiasts, researchers, and developers eager to unravel the gastronomic landscapes of these two European nations. From quaint cafes to fine dining establishments, scraping data from popular review platforms and local directories reveals a wealth of information, including restaurant names, addresses, cuisines, reviews, and ratings. This article will guide you through the ethical and practical considerations of scraping restaurant data, providing insights into Luxembourg and Norway's diverse culinary offerings. Join us as we navigate the digital realm to uncover the flavors, ambiance, and uniqueness that define the restaurant scenes in these captivating countries.
List of Data Fields
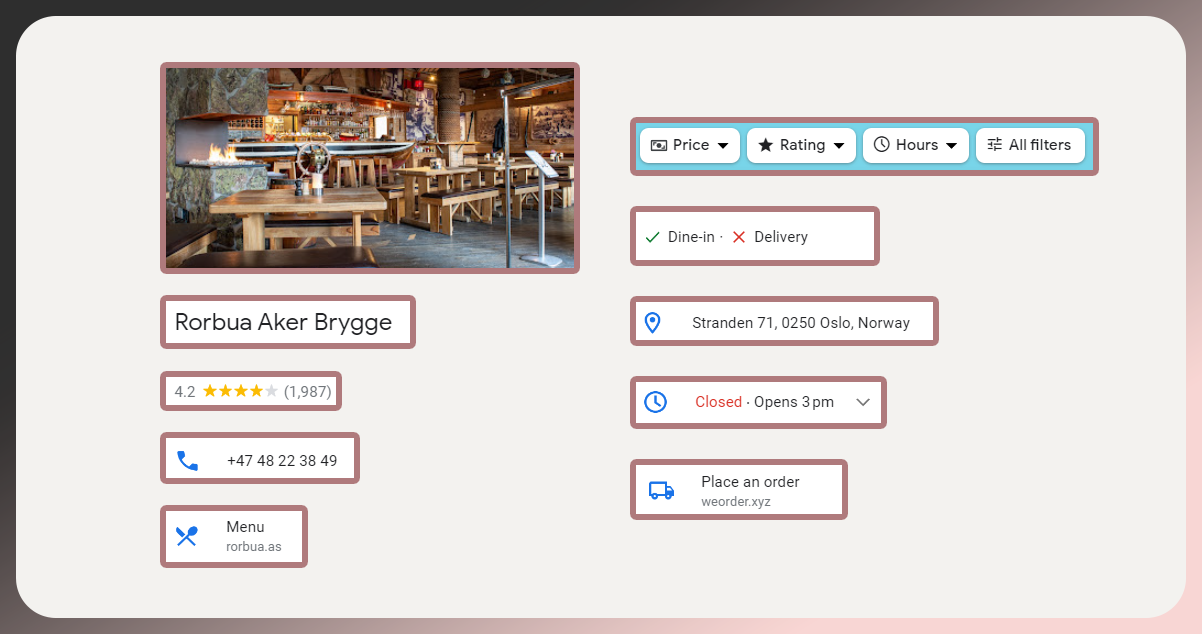
- Restaurant URL
- Restaurant Type
- Restaurant Name
- Rating
- Offers
- Variety Of Cuisines
- Discounts
- Cost Per Person
- Logo Image URL
- Address
- Opening Hours
- Sub Location
- Menu Image URL
Tools for Web Scraping
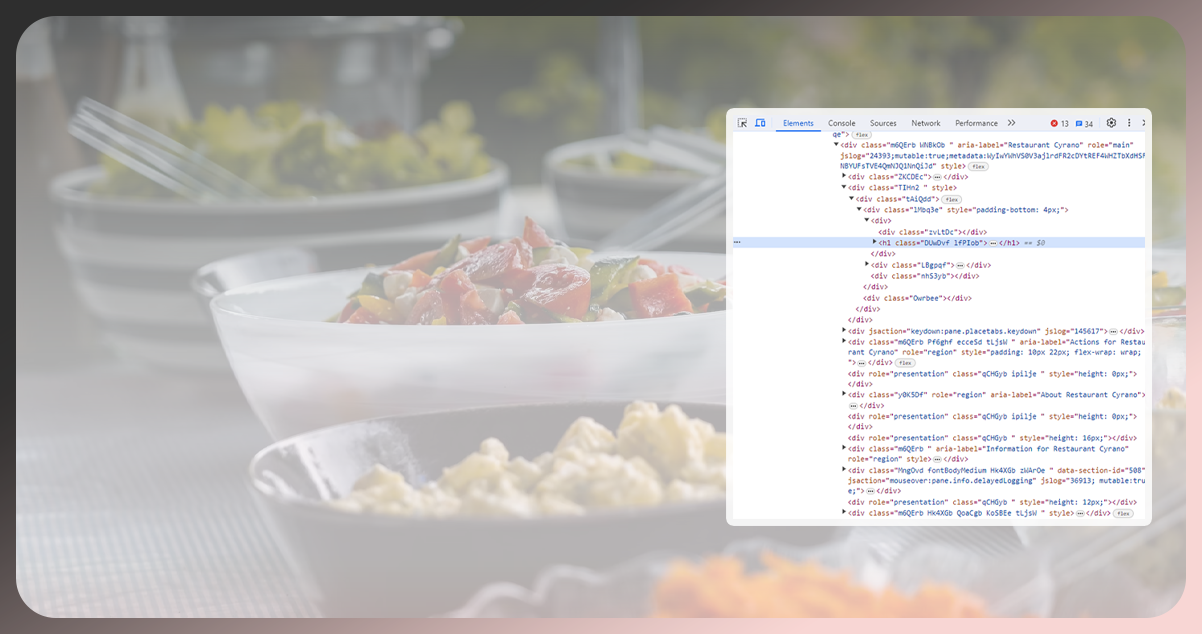
Beautiful Soup: Beautiful Soup is a robust Python library that simplifies data extraction from HTML and XML files. This tool is precious for web scraping endeavors due to its capacity to navigate and dissect the parsed tree structure of a webpage. With Beautiful Soup, developers can effortlessly pull specific data elements from the HTML or XML, facilitating the creation of streamlined and effective web scraping scripts.
This library excels in transforming complex HTML documents into a navigable tree of Python objects, allowing users to traverse the structure and locate desired information. Its syntax is intuitive, making it accessible for beginners and experienced developers engaged in web scraping projects.
Scrapy: Scrapy emerges as a robust, open-source web crawling framework for Python, providing a comprehensive set of predefined rules and conventions. This framework is particularly advantageous for projects requiring structured data extraction from websites. Scrapy follows the don't-repeat-yourself (DRY) principle, enabling developers to write efficient and modular code.
One of Scrapy's key strengths lies in its ability to define the navigation and extraction logic separately, enhancing code maintainability. Its extensibility and versatility make it popular for handling complex scraping scenarios and managing large-scale projects. Scrapy also has built-in support for handling entire web scraping tasks, such as following links and handling cookies.
Selenium: Selenium, a dynamic and versatile tool, empowers developers to control web browsers programmatically. This tool is precious when dealing with dynamic websites that generate JavaScript content. Selenium can be seamlessly integrated with Python, providing an automated means of interacting with web pages, submitting forms, and capturing dynamically loaded content.
What sets Selenium apart is its ability to emulate user interaction with a webpage, automating tasks that would require manual intervention. It is particularly advantageous for scenarios where traditional scraping methods might fall short. Selenium's integration with popular browsers and support for headless browsing further enhances its capabilities, making it a go-to solution for a wide range of web scraping challenges.
Scraping Restaurant Data: A Step-by-Step Guide for Luxembourg and Norway
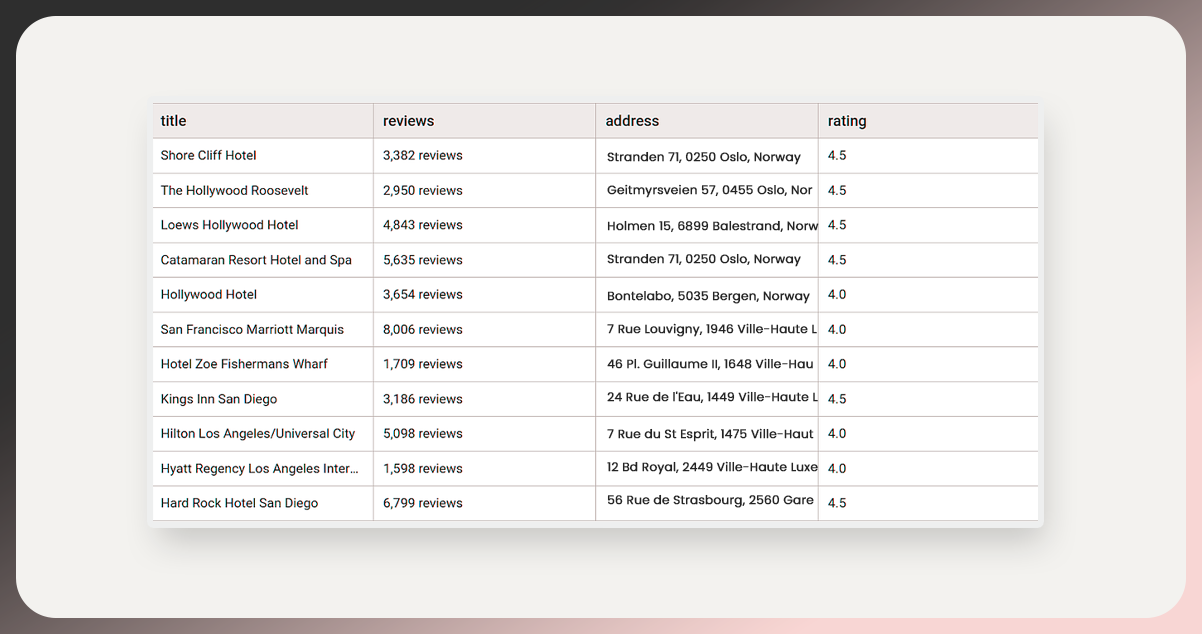
Restaurant data scraping is a powerful technique for collecting valuable information from websites. The process can be particularly insightful for businesses and researchers when gathering restaurant data for Luxembourg and Norway. Follow this detailed guide to navigate the web scraping process effectively and ethically.
Identify Target Websites: For restaurant data collection, start your web scraping journey by pinpointing the websites that host restaurant data for Luxembourg and Norway. Popular review platforms or local business directories are excellent starting points. These platforms often aggregate diverse restaurant information, including names, addresses, contact details, ratings, and reviews.
Inspect Website Structure: Dive into the structure of the identified websites using browser developer tools. This step involves analyzing the HTML elements that house the pertinent information. Identify tags and classes encapsulating restaurant details, such as divs containing names, spans for ratings, and review paragraphs. Understanding the website's structure is crucial for effective data extraction.
Set Up Your Environment: Before delving into the code, set up your development environment. Install essential libraries and tools for web scraping, including Beautiful Soup, Scrapy, and Selenium. Creating a virtual environment ensures that your dependencies are efficient, minimizing potential conflicts with other projects.
Write Scraping Code: You can develop Python scripts tailored to scrape the relevant restaurant data. Leverage the chosen libraries (Beautiful Soup, Scrapy, or Selenium) to navigate the HTML structure of the websites and extract desired information. Craft code that adheres to best practices, respecting the website's terms of use and guidelines. Implement features like rate limiting to prevent making too many requests and potentially facing IP blocking.
Handle Dynamic Content: If the target websites use dynamic content loaded through JavaScript, consider employing Selenium. Selenium lets you interact with the pages programmatically, capturing data after it renders fully. It is crucial for scraping information from websites that rely on client-side scripting for content display.
Data Storage: Decide an appropriate method for storing the scraped restaurant data. Utilize databases like MySQL or MongoDB to organize the information efficiently. Structuring your data in a database facilitates easy querying and analysis, enabling you to derive meaningful insights from the collected information.
Respect Robots.txt: Before initiating your scraping activities, consult the robots.txt file of the target websites. This file outlines rules website administrators set regarding web crawlers' acceptable behavior. Adhering to these guidelines is vital for ethical web scraping and helps maintain a positive relationship with the websites you extract data from.
Conclusion: The ethical web scraping of restaurant data from Luxembourg and Norway reveals a rich tapestry of culinary insights. Through meticulous extraction from platforms, our restaurant data scraping services navigated website structures, crafted Python scripts, and responsibly handled dynamic content. The deployment of tools like Beautiful Soup, Scrapy, and Selenium, coupled with reasonable data storage, ensures a wealth of information for strategic analysis. Adherence to robots.txt guidelines underscores the commitment to ethical practices. This endeavor of using a restaurant data scraper captures the essence of local dining scenes and sets the stage for informed decision-making in these gastronomic landscapes.
For profound insights, connect with Food Data Scrape. We specialize in Food Data Aggregator and Mobile Restaurant App Scraping, offering comprehensive data analytics and insights to enrich your decision-making and elevate your business strategies. Reach out today to unlock a pathway to success guided by data-driven intelligence.





