






















































































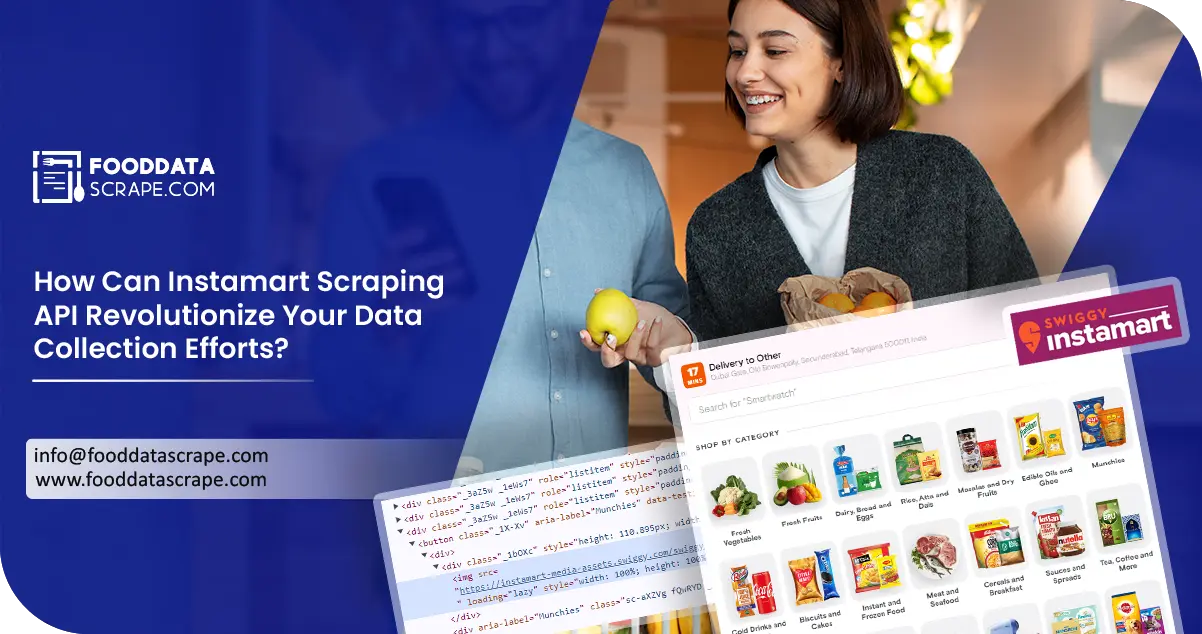
The Client
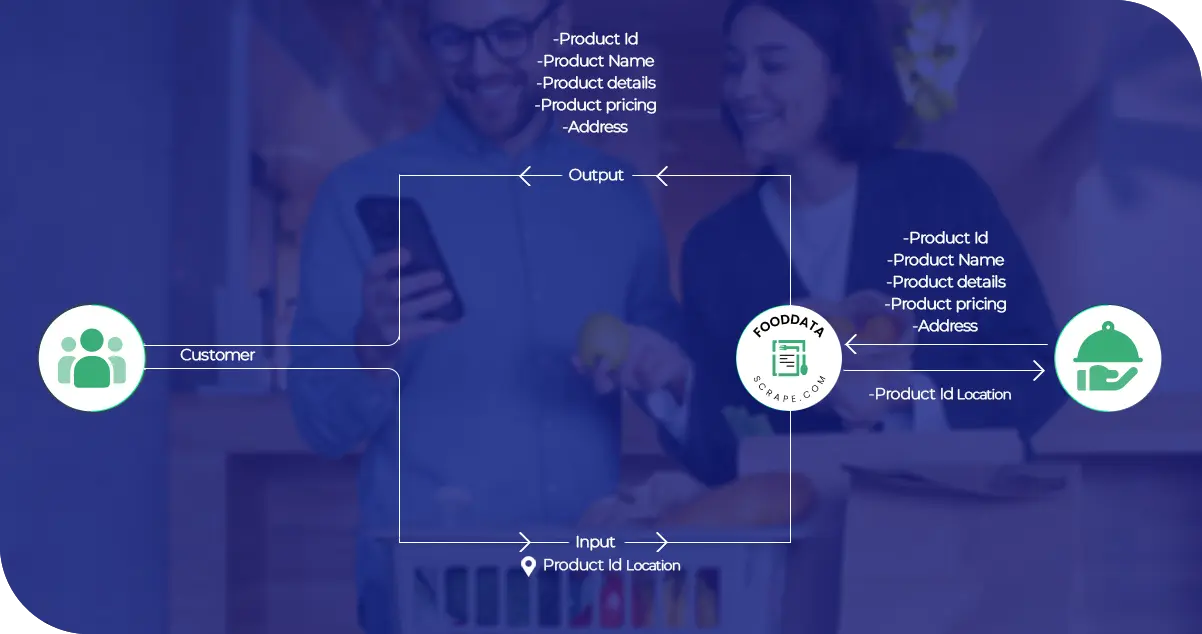
Our client, who sells groceries online, wants to get data from Instamart. Hence, they opted for our Instamart scraping API for the swift extraction process. This tool will help them collect vital information for market analysis, inventory management, and strategic decisions. Through our API, they can access actual-time knowledge regarding product availability, pricing fluctuations, and customer preferences on the Instamart platform. It gives them the power to adjust their operations and improve customer satisfaction.
Key Challenges
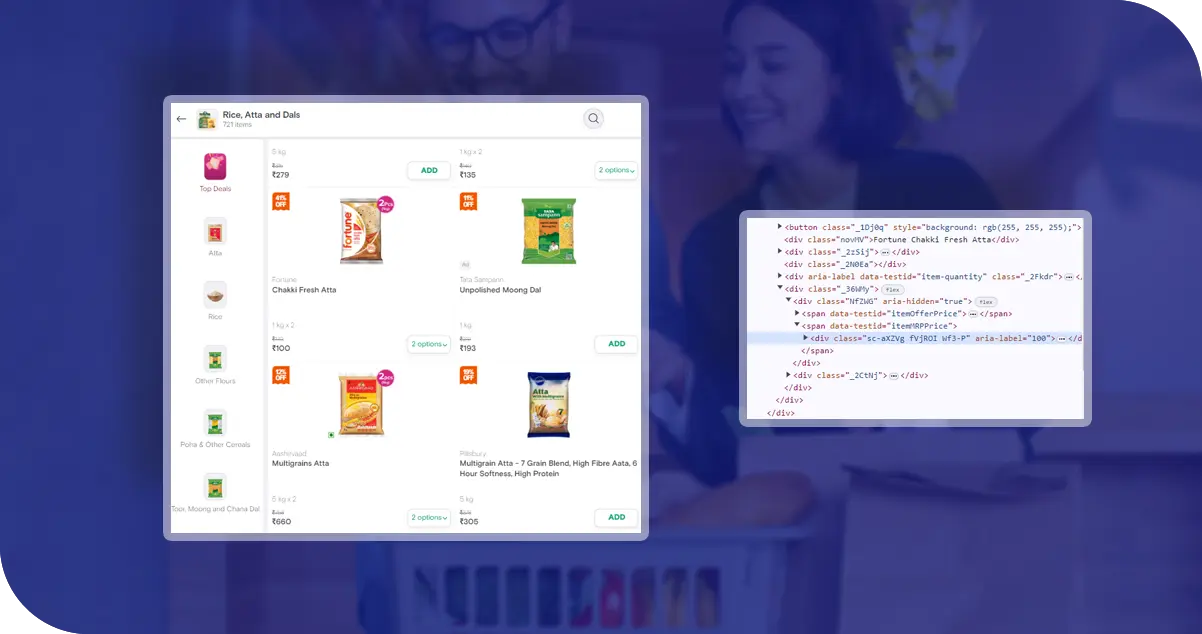
Dynamic Website Structure: The client found difficulties with Instamart's often-changing website design, which has a dynamic architecture. This diversity shows the problem of data scraping because different versions of a web page require constant and appropriate adaptation.
Anti-Scraping Measures: Instantmart implements anti-scraping techniques such as CAPTCHA challenges and IP blocking to deter data extraction. It takes advanced methods to prevent getting caught and continue the data scraping process.
Data Quality and Consistency: Maintaining data quality and integrity is challenging because of user-guided content and changing Instamart inventory. A stringent verification mechanism and recurrent scans are needed.
Key Solutions
Structured Data Extraction: Through the Instamart scraper, it has become possible for our client to overcome the issue of the dynamic website structure. The API is equipped to extract data from the Instamart webpage when it undergoes frequent changes to its layout, resulting in consistency and reliability in data collection.
Anti-Scraping Mitigation: The grocery data scraper is designed to bypass Instamart's anti-scraping procedures. It employs sophisticated solutions like IP rotation and user-agent emulation to facilitate a smooth query while minimizing the risk of detection and IP blockage.
Data Quality Assurance: Our client can increase data quality and consistency through our grocery data scraping services. The API encompasses a set of internal validity checks to ascertain the extracted data, thus providing accurate product descriptions, pricing, and inventory details. It maintains the quality of data for accurate and informed decision-making.
Methodologies Used
HTML Parsing: We applied HTML parsing libraries like BeautifulSoup in Python to analyze the structure of Instamart's web pages to extract the data we needed. This method allowed us to traverse the HTML elements and extract product details, prices, and availability details.
XPath Queries: We used XPath queries to get data by targeting particular elements within the HTML document. With XPath, you can easily navigate a web page's XML-like structure and select your preferred data.
API Integration: If available, we connected with Instamart's official APIs to get the structured data directly from their server. This method allowed us to retrieve data more reliably and effectively than web scraping, as no HTML parsing or dynamic building was needed.
Headless Browser Automation: We used Selenium and other headless browser automation tools to mimic interactions with Instamart's site as a human user does. This approach enabled us to fake user actions such as clicking buttons, filling forms, and scrolling through pages to access and collect data dynamically loaded via JavaScript.
Proxy Rotation: Use proxy rotation methods to avoid anti-scraping measures, including IP blocking. To mask the requests we sent through a pool of different IP addresses, we performed scraping activities that looked like regular user traffic, allowing us to remain undetected and continuously extract the desired data.
Advantages of Collecting Data Using Food Data Scrape
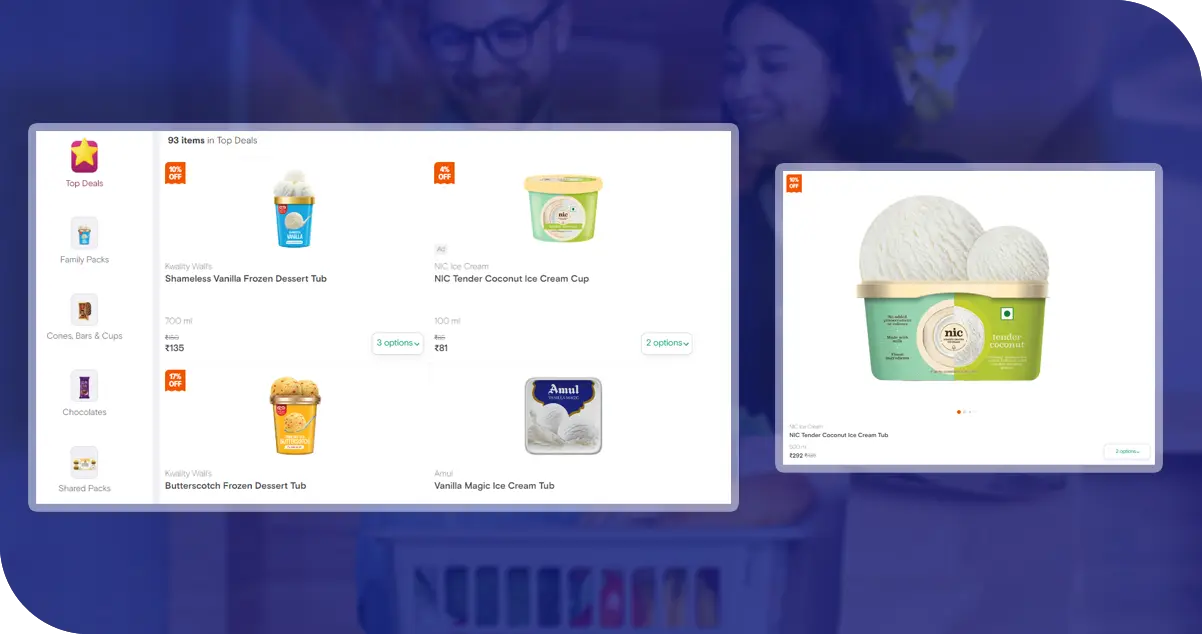
Comprehensive Expertise: We offer our clients a team of experienced specialists with knowledge of different scraping methods to cover scraping requests across a wide range of domains. Whether it is web scraping, integrating APIs, or advanced data mining, we can provide customized solutions.
Customized Solutions: We understand that each scraping project is different and sometimes requires custom-created solutions to ensure the best results. We work closely with clients and perform in-depth analyses to create personalized scraping strategies tailored to their business demands and objectives.
Scalability and Efficiency: With top-notch infrastructure and scalable architecture, we can quickly tackle scraping projects of any size. Whether scraping data from a single website or multiple sources, we ensure high performance and fast results delivery.
Compliance and Security: We emphasize legal and ethical compliance in all our scraping activities. In our processes, we follow data protection rules and website terms of service, an essential step toward avoiding legal disputes and preserving our reputation. Furthermore, we adopt thorough security measures to protect data and avoid illegal entry or attacks.
Continuous Support and Maintenance: Our dedication to customer service is not limited to project completion. We offer continuous support, maintenance, and monitoring services to maintain the effectiveness and reliability of scraping solutions. Regardless of our challenges, from troubleshooting and adjustments to site changes to adding extra functionalities, we stay committed to continually creating value for our customers.
Final Outcome: Our Instamart API allowed us to solve our client's data collection problems. By adeptly scraping data from Instamart's dynamically changing website, we gave real-time insights into product availability, price trends, and customer preferences. Equipped with accurate and timely information, the client succeeded in operations optimization, improved inventory management, and evidence-based decisions to propel business growth and customer retention.

